Als Deep Learning bezeichnet man eine Methode, Computer selbstständig lernen zu lassen. Dies ist vor allem im Bereich der künstlichen Intelligenz sehr wichtig. Als sehr effizient hat sich dabei die Benutzung neuronaler Netze erwiesen, die dem menschlichen Gehirn nachempfunden sind. Auch die Science-Fiction Literatur liebt diesen Begriff. Aber was sind neuronale Netze eigentlich? Und wie funktionieren sie?
Unser Gehirn besteht aus Billionen von Nervenzellen (Neuronen), die alle miteinander auf bestimmte Weise verknüpft sind. Ein einzelnes Neuron hat eigentlich nur eine Aufgabe: ein Signal zu empfangen und – sofern es stark genug ist und einen bestimmten Schwellwert überschreitet – es an andere Neuronen weiterzuleiten.
Die Gesamtheit der an einem Erkennungsprozess beteiligten Neuronen bestimmt dann, was vom Gehirn erkannt wird.
Beim Deep Learning ist ein „Neuron“ im Grunde nur eine simple Funktion, die eine klare Aufgabe hat: eine Information zu empfangen, sie nach bestimmten Regeln auszuwerten und ihr so eine Wichtung, einen bestimmten Wert zuzuweisen. Dieser Wert reicht meist von 0 (nicht interessant) bis 1 (sehr zutreffend). Nach dieser Wertung leitet das Neuron diesen Wert an weitere Neuronen weiter, sofern er eben einen bestimmten Schwellwert überschreitet, also interessant erscheint. Und so geht das über viele Schichten, wobei die Wertung unseres Eingangssignals mit jeder Schicht immer genauer und zutreffender wird.
Ein Beispiel
Wir möchten dem Computer beibringen, selbstständig Zahlen von null bis neun zu erkennen. Wenn diese Zahlen auch noch handschriftlich vorliegen, ist das kein einfaches Unterfangen, denn: je nach Handschrift kann eine „1“ grosse Ähnlichkeit mit einer „7“ haben, eine „3“ könnte man vielleicht für eine „8“ halten. Also wie gehen wir vor?
Zuerst zerlegen wir das Eingangsbild (eine Zahl von null bis neun) in einzelne Bildpunkte (Pixel). In unserem Beispiel zerlegen wir jede Zahl in ein Gitter von 28 mal 28 Bildpunkten, insgesamt also 784 einzelne Punkte.
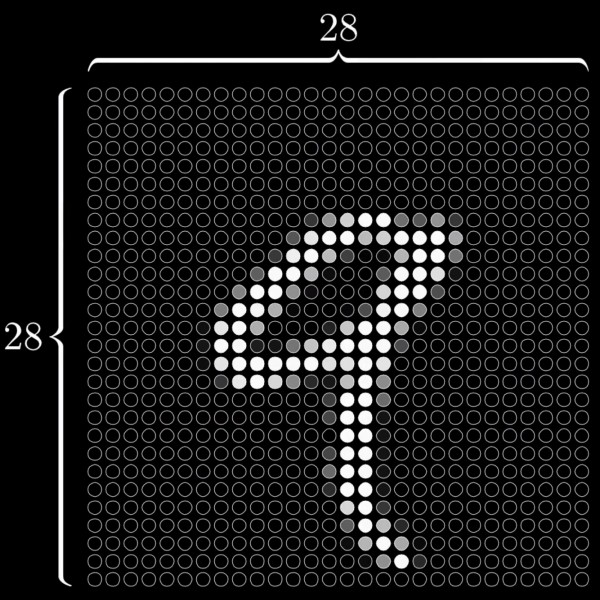
Jeden dieser 784 Pixel senden wir nun an ein eigenes Neuron, das nur eine Aufgabe hat: zu untersuchen, ob dieser Bildpunkt schwarz ist (also leer), weiss (hier wurde also „Tinte“ gefunden) oder irgendetwas dazwischen.
Ist der betreffende Bildpunkt schwarz, also leer und damit uninteressant, vergibt das betreffende Neuron, das dieses Bildpunkt verarbeitet, den Wert 0. Ist er weiss, vergibt das Neuron den Wert 1. Weist dieser Bildpunkt einen Grauwert auf, vergibt das Neuron irgendeinen Wert zwischen 0 und 1, je nach Helligkeit des Pixels, also z.B. 0,5.
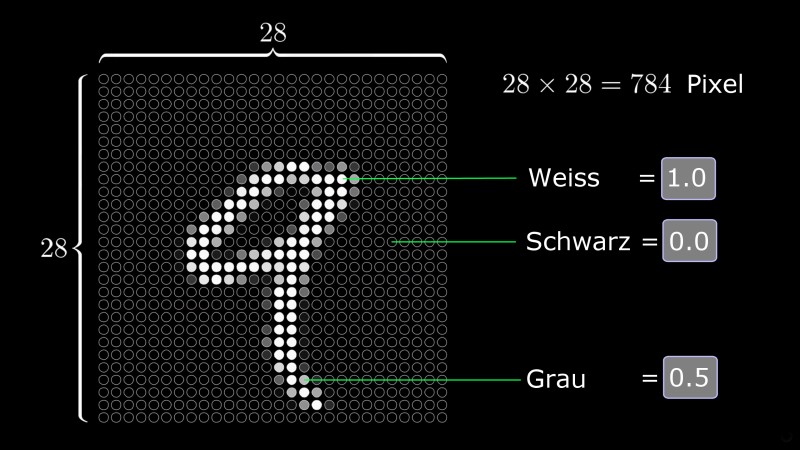
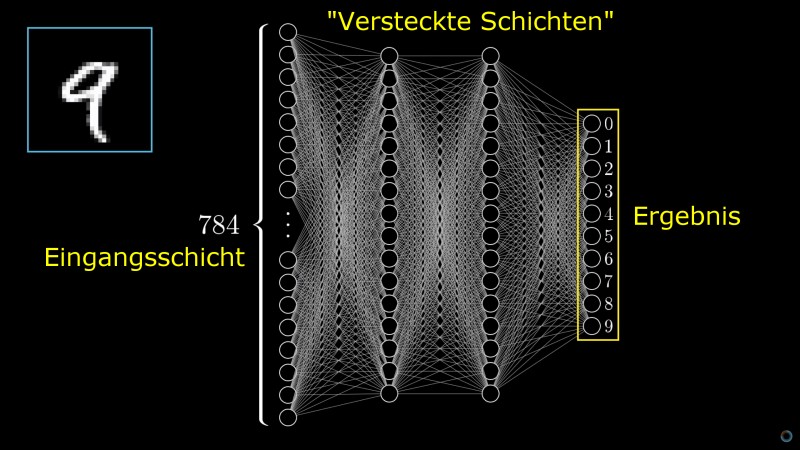
Diese 784 Neuronen (eines für jeden Pixel des Zahlenbilds) stellen die erste Schicht („Layer“) unseres neuronalen Netzwerks dar.
Die letzte Schicht unseres Netzwerks hat dagegen nur noch zehn Neuronen: eines für jede Zahl, die wir zu erkennen hoffen. Wird also ganz am Schluss zum Beispiel das Neuron aktiviert, das für die Zahl „1“ steht, haben wir hoffentlich eine 1 erkannt.
Zwischen dieser allerletzen Schicht von Neuronen und der ersten, die ja direkt mit den Pixeln des Eingangsbildes gefüttert wurde, liegen nun aber noch viele weitere Schichten, die gegen Ende aus immer weniger Neuronen bestehen. Die erste Neuronenschicht sendet ihre Signale an die zweite Schicht weiter, wo diese wieder ausgewertet und die Auswahl somit immer weiter eingeengt wird. Und dann geht es weiter zur nächsten Schicht usw. – bis wir irgendwann bei unserer letzten Neuronenschicht landen, die nur noch aus zehn Neuronen besteht und uns dann hoffentlich sagt, um welche Zahl es sich wohl handelt.
Warum funktioniert das?
Dieser Prozess des Lernens funktioniert deshalb, weil jedes Eingangsbild ein ganz bestimmtes Muster in unseren verschiedenen Neuronenschichten auslöst, je nachdem, an welcher Stelle des Bildes sich helle oder schwarze (leere) Bildpunkte befinden. Trainiert man das nun mit vielen, vielen Eingangsbildern wird klar, das bestimmte Zahlen auch immer sehr ähnliche Neuronenmuster erzeugen. So erkennt der Computer irgendwann, das diese oder jene Neuronen sich in der Regel bei der Zahl „9“ aktivieren, oder jene bei der Zahl „1“. So in etwa lernen auch wir Menschen.
Je mehr verschiedene Eingangsbilder für das Lernen benutzt werden, desto mehr ist der Computer auch in der Lage, mit Variationen umzugehen, also „Toleranzen“ zu akzeptieren. Dann darf eine „3“ auch mal etwas mehr Schwung haben. Egal, denn bei allen Bildern einer „3“ wird ja immer ein recht ähnliches Muster erkannt.
Anfangs wird der Computer eine „3“ noch recht häufig mit einer „8“ verwechseln, aber mehr verschiede Bilder wir ihm zum analysieren geben, desto treffsicherer wird er und desto genauer kann er feine Unterschiede auseinander halten.

Was „sehen“ die Neuronen?
Wir haben oben ja schon geschrieben, das jedes einzelne Neuron eigentlich nur einen Wert empfängt, ihn auswertet und an andere Neuronen weiterleitet. Das Muster, das in Gesamtheit dadurch entsteht, kann man aber tatsächlich mit dem Sehen vergleichen. Denn wenn wir betrachten, welche Neuronen bei bestimmten Zahlen aktiviert werden, finden wir heraus, das sie bestimmte Gemeinsamkeiten in unseren Eingangsbildern erkennen: Kreise, Striche, Bögen usw.
Durch das Weiterleiten der Eingangsinformationen von einer Neuronenschicht zu nächsten wird die Eingangsinformation immer weiter abstrahiert, so das der Computer in etwa folgendes „sieht“:

Das ist natürlich nur eine stark vereinfachte Erklärung, um zu demonstrieren, wie Deep Learning funktioniert. Da maschinelles Lernen, KI und vor allem Deep Learning in unserem Alltag aber eine immer grössere Rolle spielen – sei es in selbstfahrenden Autos oder bei der Vergabe von Krediten – sollte auch jeder Bürger, zumindest im Ansatz, verstehen, wie dieser Prozess, zumindest im Ansatz, funktioniert.
Seltsam? Aber so steht es hier geschrieben... Ihr habt Fragen, Anregungen oder vielleicht sogar eine völlig andere Meinung zu diesem Artikel? Dann postet einen Kommentar.
 Autor: Mike vom Mars
Autor: Mike vom Mars
Mike emigrierte vor einigen Jahren von seinem Heimatplaneten auf die Erde, um das Leben am wohl seltsamsten Ort des Universums zu studieren. Seiner Bitte "bringt mich zu eurem Führer" wurde bisher nicht entsprochen.
 SHIRTS & HOODIES
SHIRTS & HOODIES